VLURes: Understanding Vision and Language Across Cultures
A New Benchmark for Smarter, More Equitable AI
Jesse Atuhurra1, Iqra Ali2, Tomoya Iwakura3, Hidetaka Kamigaito1, and Tatsuya Hiraoka1,4
1 NAIST 2 QMUL 3 Fujitsu Ltd 4 MBZUAI
Despite recent advances in Vision-Language Models (VLMs), most benchmarks evaluate models in English, with limited regard for non-English languages or rich, real-world contexts. This monolingual bias severely limits how we assess AI’s true generalization capabilities, especially for low-resource languages.
VLURes is designed to change that. It rigorously evaluates visual and linguistic understanding across English, Japanese, Swahili, and Urdu, using diverse tasks, rich prose, and grounded cultural contexts.
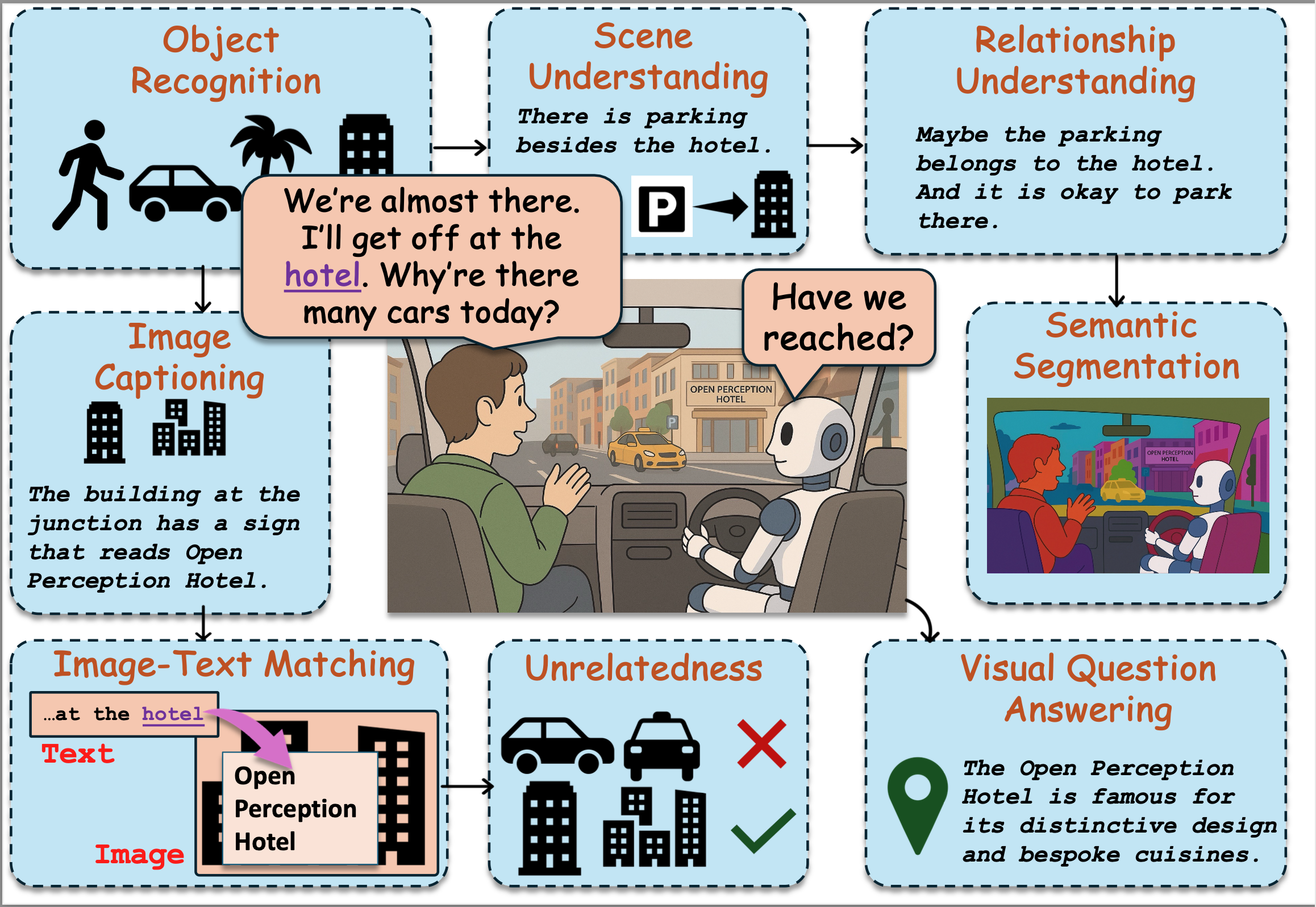 Figure 1: VLURes Task Overview
Figure 1: VLURes Task Overview
VLURes is more than just a dataset; it’s a comprehensive testbed for the next generation of intelligent agents.
- Truly Multilingual: We collected 1,000 culturally-relevant image-text pairs for each of four languages: English, Japanese, Swahili, and Urdu.
- Rich, Real-World Context: Instead of short captions, each image is paired with a full article, forcing the AI to reason about deep, contextual information.
- A New Test of “Unrelatedness”: We introduce a novel task that challenges models to identify and ignore textual information that is not related to an image—a crucial skill for navigating noisy, real-world data.
VLURes is a multilingual vision-language benchmark aimed at testing intelligent agents under realistic conditions. Each input contains an image and an article-level text (not just captions), and the benchmark tests a model’s ability to perform both image-only and image+text reasoning.
VLURes covers 8 tasks:
- Object Recognition (OR)
- Scene Understanding (SU)
- Relation Understanding (RU)
- Semantic Segmentation (SS)
- Image Captioning (IC)
- Image-Text Matching (ITM)
- Visual Question Answering (VQA)
- Unrelatedness (newly introduced)
We collected articles and images from multiple web sources, including Wikipedia, Wikinews, blogs, and forums. The collection covers diverse topics such as animals, locations, food, buildings, and events.
- Languages: English (En), Japanese (Jp), Swahili (Sw), Urdu (Ur)
- Image-Text Pairs: 1000+ pairs per language
- Rich Context: Full-length articles, not just captions
- Cultural Coverage: Data sourced from native content in all four languages
We used CLIP similarity scores to align the most relevant image to each article. All data was cleaned manually, filtered for quality, and checked for NSFW or offensive content.
The proposed Unrelatedness task. Left: The VLM inputs consist of two modalities, a pair of images and texts. The image undergoes a series of transformations in the vision encoder and connector, generating visual tokens that are ready for alignment in a shared embedding space. Similarly, a tokenizer tokenizes text, generating textual tokens. Textual and visual tokens are aligned in a shared embedding space and fed as input to the LLM. Right. The LLM uses its multimodal understanding to decide what textual information is relevant to different parts of the image. We see that the text painted green (marked with a cross sign) is directly related to the region of the image shown inside a green square box. That is, the text matches the image part shown in green. But in this task, we are interested in text unrelated to the image. Hence, yellow text (marked with a check sign) answers our Unrelatedness task.
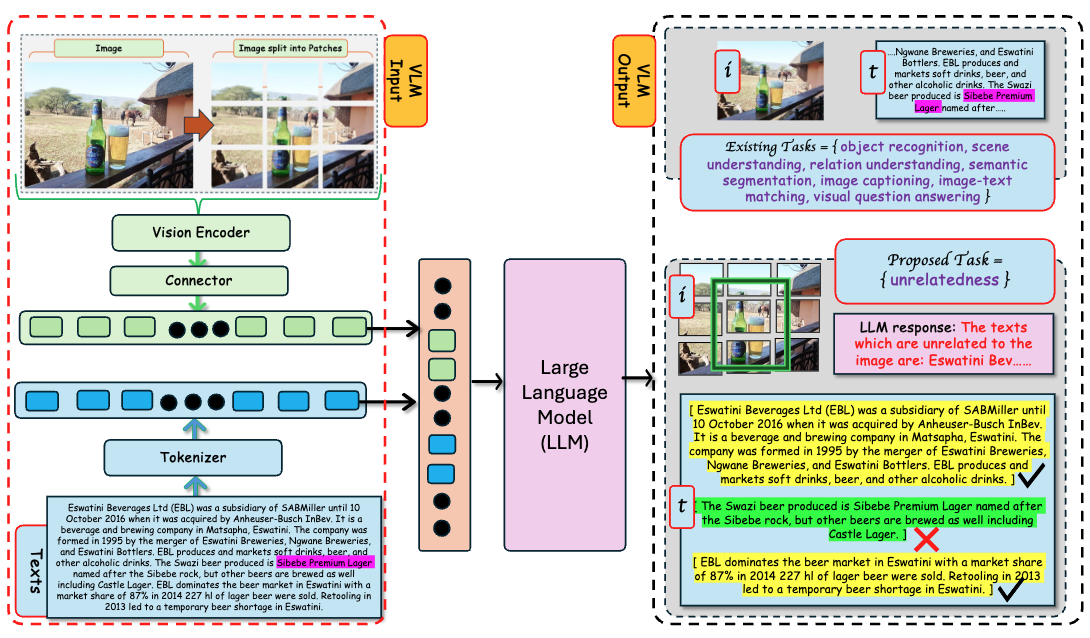 Figure 2: Our proposed Unrelatedness Task
Figure 2: Our proposed Unrelatedness Task
Unlike traditional matching tasks, Unrelatedness tests whether a model can identify irrelevant information. This is vital in noisy, multimodal environments like news feeds or social media.
Can the model ignore text that does not describe or relate to the image?
This is the inverse of standard grounding tasks and pushes models to reason beyond associations.
- Task Definition: 8 vision-language tasks
- Data Collection: From native-language web sources
- Alignment: Image selection via CLIP similarity
- Evaluation: Via human and automatic judges
- Results: Quantitative accuracy + qualitative rationale analysis
Models were tested under:
- Zero-shot and One-shot settings
- With and without rationales
- Before and after fine-tuning
We used both:
- Automatic evaluation: via Gemini 1.5 Pro (“LLM-as-a-Judge”)
- Human evaluation: native speakers rated output quality on a 1–100 scale
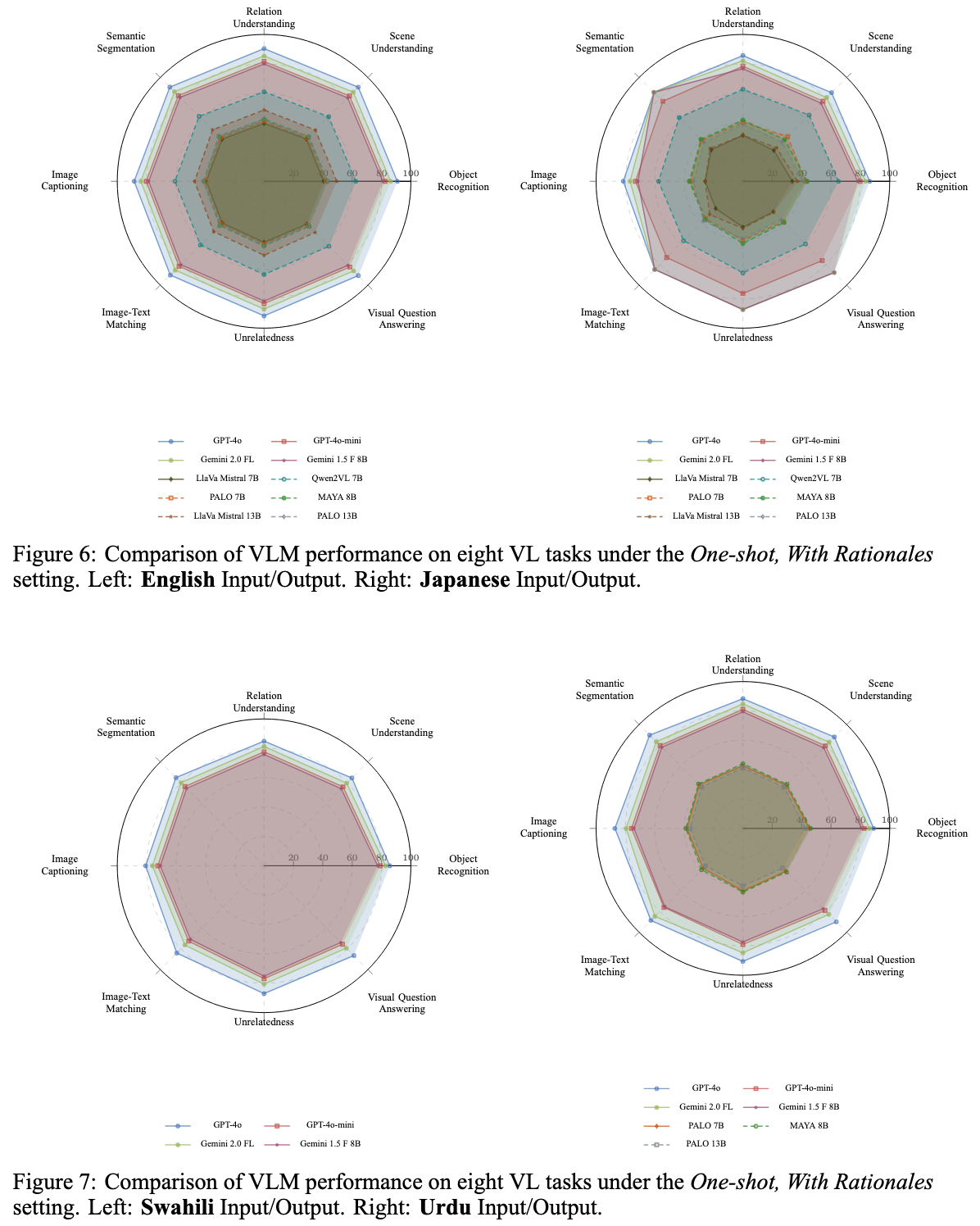
- GPT-4o is the top performer across all settings but still trails human performance, especially for Swahili and Urdu.
- Rationales help: prompting models to “show their work” consistently improved accuracy.
- Open-source models like Qwen2VL and PALO significantly benefit from fine-tuning, but struggle with Swahili and Urdu input.
- Multilingual drop: performance degrades in the order En → Jp → Ur → Sw, showing clear signs of language bias.
- Poor Swahili/Urdu coverage in even the strongest open-source models
- Lack of robustness in outputs when prompts and answers are in different languages
- Language alignment (En input + En output) still yields the best performance
- Rationale prompting significantly closes the gap between open-source and proprietary models
We believe in open science. All assets are publicly available:
🧑💻 Authors
For questions about this research, please get in touch with the corresponding authors:
- Jesse Atuhurra (
atuhurra.jesse.ag2@naist.ac.jp) - Tatsuya Hiraoka (
tatsuya.hiraoka@mbzuai.ac.ae)
📚 BibTeX
BibTex coming soon...
Usage and License Notices
The code, annotations, and other original materials in this repository are licensed under the Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License (CC BY-NC-SA 4.0).